Data Science Skills
Updated on
This article discusses the data science skills necessary at every stage of the lifecycle of production-level data science and machine learning systems. It is a result of a cumulative professional experience of authors at JobsInData.
There are two types of data science skills: core skills and enablers. Both are critical for data scientists to master, although some may be more important depending on your current data science career level.
Compared to other skill lists for data scientists, the top data science skills list presented in this article focuses on the following aspects:
- Skills needed for production-grade data science systems
- Skills enabling maximization of your lifetime data science salary
- Skills required for different stages of a data science career path and their impact on career progression
- Data science resources to improve your data science resume
Overview - the Data Science Skills Matrix
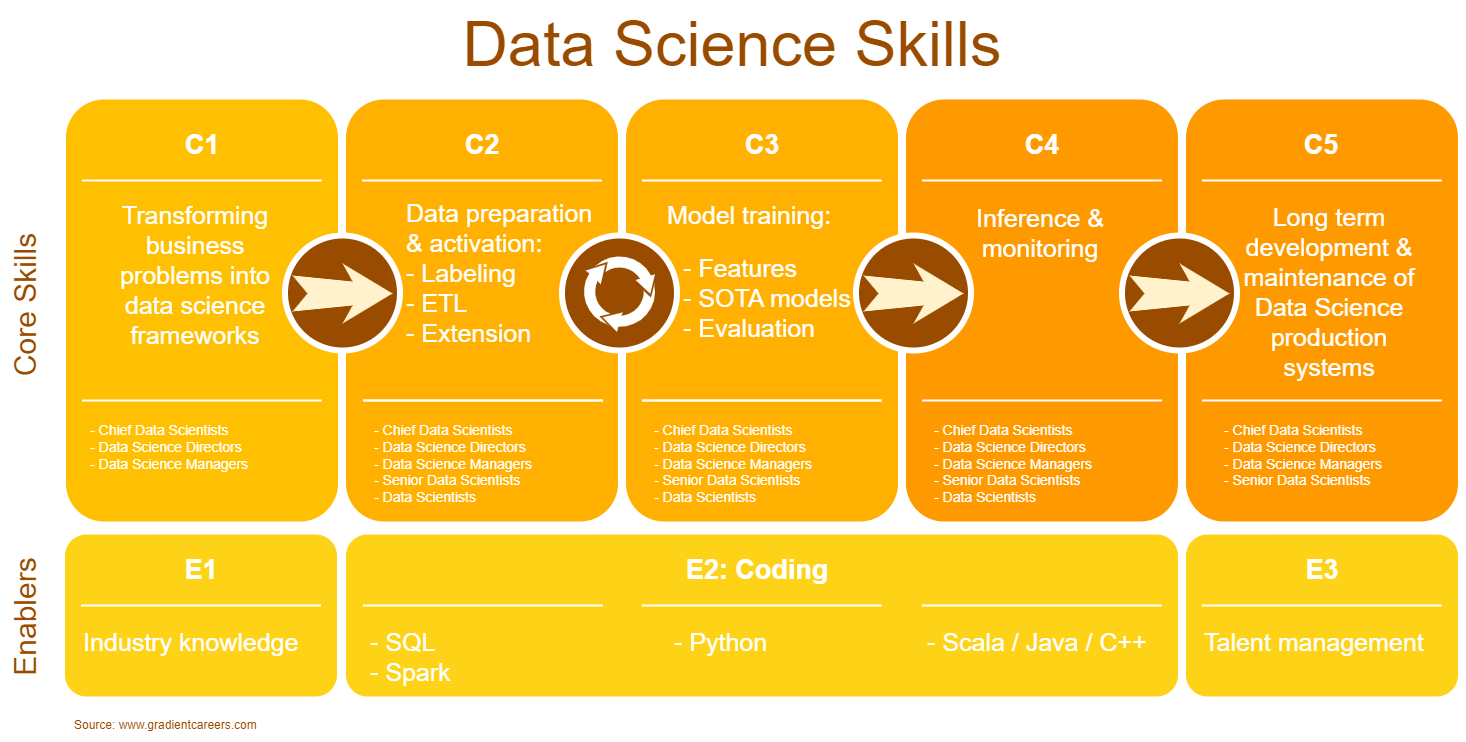
The core Data Science skills:
- C1. Transforming business problems into data science frameworks
- C2. Data preparation & activation:
- C3. Model training:
- C4. Inference and monitoring
- C5. Long term development & maintenance of Data Science production systems
The enabling Data Science skills:
Let's deep-dive into every skill.
C1 Transforming business problems into data science frameworks
The ability to translate the needs of product teams and business teams into practical, solvable Machine Learning problems. In particular, it involves answering the following questions: - What is the target we are trying to predict? - What are the possible features? - Is there a logical causality between features and the target? - What is the logical path from the model outcomes into business decisions?An illustrative example from e-commerce recommender systems (simplified for the ease of exposition):
Business Problem: Personalise user interaction with ecommerce website: show the most relevant items to maximise the likelihood of conversion weighted by the item value. The underlying goal is to maximise the GMV - gross merchandise value.
Model specification: Target: Given that the user was shown the product, has she bought it or not? (Classification problem) Features: The historical user’s purchases up until the moment of the given impression expressed as a product-level buy2buy matrix.
Causality between features and target: Yes. Historical purchases give insight into a user's personal taste and needs, and hence could be a good predictor for future purchases.
Logical path from the model into business decision: At the moment of the request for product recommendations, rank and display Top N products according to the following formula:
E(GMV_i) = P(C_i) * Price_i
#where:
#E(GMV_i) - expected Gross Merchandise Value from showing product i to the user
#P(C_i) - probability of conversion for product i (the model’s output)
#P_i - price of product i
Critical for:
- Chief Data Scientists
- Data Science Directors
- Data Science Managers
Resources to improve:
This is a skill that comes mostly from experience & industry knowledge. However, there are quality materials out there on this topic:
- Google ML problem framing course
- Yahoo Paper on Practical Framework for CTR prediction
- Various courses at universities involving ML Case Study solving
C2. Data preparation & activation
C2a Data sources extension
Data sources extension is about bringing new data sources relevant to the problem. It is connected to, yet conceptually differt from Feature Engineering:
- Feature Engineering is about extracting the signal from the existing data
- Data sources extension is about adding new data to the problem. It might come in different forms:
- More records of the same nature
- New characteristics to enrich existing records in the database
Data sources externsion is generally more subtle and complicated than feature engineering, but unlocks signals that were not yet present in the dataset.
Critical for:
- Data Science Managers
- Senior Data Scientists
- Data Scientists
Resources to improve:
- This skill comes with industry knowledge and discussions with industry experts
- A careful consideration of all possible signals influencing the target in the model, potentially using consulting - like tools like a driver tree analysis
C2b ETL - extract, transform & load
Loading the data and preparing if for analysies - visualizations, feature engineering and model training. The key skills here are:
- Matching the data type vs business need vs the proper ETL tool. Cost considersations are very important. You want to have the most important data flexibly available for Data Science team to experiment with, however flexible solutions are typically expensive, so you put ALL of your data into flexible tools, your cloud budget will explode. Managing this tradeoff is the most desirable skill here.
- Knowledge of all of the most popular ETL tools - otherwise your recommendations will be biased by what you already know.
Critical for:
- Senior Data Scientists
- Data Scientists
Resources to improve:
- The key here is the experience coming from development and maintenance of large-scale data pipelines, hence the most prominent resource here is the time spend on such problems with top data engineers.
- Various online courses on ETL tools
C2c Data Labeling
Generating target values for training data samples. Some industries get it for free (e.g. a history of purchases in an e-commerce website is a natural target for the recommender their system models), while for others it is the most effort-intensive step in their Machine Learning pipelines (e.g. segmentation models for images or videos with many classes).Critical for:
- Data Science Managers
- Senior Data Scientists
- Data Scientists
Resources to improve:
It largely depends on the model class, but if you want to do it yourself, there are tools and techniques to streamline Data Labeling:
- If you start completely from scratch, then using simple heuristics will typically get you far (for example based on the image metadata). Remember that for a first, simple model, labels may contain noise, as you will use it to generate higher quality labels later on.
- Once you train the first model, it allows pseudo-labelling and iteration to generate higher quality labels
- Sometimes you don't have labelled data available for your exact problem, but for a similar problem. Using your creativity, you can take advantage of it. Here is a great example from microscoping images, of moving from weak image-level labels to cell level labels.
- For a general data labeling strategy please consider an Active Learning approach
There are also companies that will do you for you (but not for free):
C3. Model training:
C3a State Of The Art (SOTA) Machine Learning models
For many the most exciting part of Data Science, often confused with Data Science or Machine Learning as entire domains. The core skill here is to quickly assess which model class is relevant to solve the task at hand.If you are not sure which model best suits your use-case, we propose the following heuristic for selecting a model class:
| Data type | Proposed Model |
|---|---|
| Tabular, Time series, Events stream | LGBM |
| Image, Text , Sound | Neural Networks |
The above heuristic is based on winning solutions to open problems on Kaggle, as well as combined experience of authors at gradientcareers. Why Kaggle? We believe in the free market, where all Machine Learning model classes compete on an equal basis, and thousands of teams spend months researching the optimal models. In the table below we summarize the SOTA Machine Learning models based on Kaggle competitions in 2022.
State of the art (SOTA) Machine Learning models in 2022
| Competition Name | Numer of competing teams | Data Type | Machine learning problem class | Winning (SOTA) Machine Learning model |
|---|---|---|---|---|
| Feedback Prize - English Language Learning | 2654 | Text | Regression | Neural networks: - microsoft-deberta-v3-base - deberta-v3-large - deberta-v2-xlarge - roberta-large - distilbert-base-uncased |
| Open Problems - Multimodal Single-Cell Integration | 1220 | Single-cell multiomics data | Multimodal + Correlation | Neural networks - custom architecture |
| RSNA 2022 Cervical Spine Fracture Detection | 883 | Images | Classification | Neural networks: - resnet 18d unet - effv2 - convnext tiny - convnext nano - convnext pico - convnext tiny - nfnet l0 |
| Google Universal Image Embedding | 1022 | Images | Creating image representations | Neural Networks: - ViT-H - ViT-L |
| Mayo Clinic - STRIP AI | 888 | Images | Classification | Neural Networks: - swin_large_patch4_window12_384 |
| HuBMAP + HPA - Hacking the Human Body | 1175 | Images | Segmentation | Neural networks: -1x SegFormer mit-b3 - 2x SegFormer mit-b4 - 1x SegFormer mit-b5 - SegFormer mit-b5 |
| American Express - Default Predictio | 4874 | Tabular | Classification | Gradient Boosted Decision Trees: - LGBM |
| Feedback Prize - Predicting Effective Arguments | 1557 | Text | Classification | Neural networks: - deberta-(v3)-large |
| Google AI4Code – Understand Code in Python Notebooks | 1135 | Text | Regression | Neural networks: - deberta-(v3)-large |
| UW-Madison GI Tract Image Segmentation | 1548 | Images | Segmentation | Neural networks: 4 unets, with efficientnet b4, b5, b6, b7 backbones |
| Foursquare - Location Matchin | 1079 | Tabular | Classification | Gradient Boosted Decision Trees + Neural Networks: - LGBM - Bert |
| Kore 2022 | 469 | - | Game | Rule-based |
| JPX Tokyo Stock Exchange Prediction | 2033 | Time series | Regression | Gradient Boosted Decision Trees: - LGBM |
| Image Matching Challenge 2022 | 642 | Images | Classification | Neural networks: LoFTR SuperGlue DKM |
| U.S. Patent Phrase to Phrase Matching | 1889 | Text | Regression | Neural networks: - microsoft/deberta-v3-large - anferico/bert-for-patents - ahotrod/electra_large_discriminator_squad2_512 - Yanhao/simcse-bert-for-patent - funnel-transformer/large |
| March Machine Learning Mania 2022 - Men’s | 930 | Tabular | Classification | Gradient Boosted Decision Trees: - XGB |
| March Machine Learning Mania 2022 - Women's | 651 | Tabular | Classification | Gradient Boosted Decision Trees: - LGBM |
| BirdCLEF 2022 | 807 | Sound | Classification | Neural Networks: - tf_efficientnet_b3_ns - eca_nfnet_l0 |
| H&M Personalized Fashion Recommendations | 2952 | Events' stream | Recommendation system (classification) | Gradient Boosted Decision Trees: - LGBM |
| NBME - Score Clinical Patient Notes | 1471 | Text | Named Entity Recognition | Neural Networks: - deberta-v3-large - deberta-v2-large - deberta-large |
| Happywhale - Whale and Dolphin Identification | 1588 | Images | Classification | Neural Networks: - efficientnet_b5 - efficientnet_b6 - efficientnet_b7 - efficientnetv2_m - efficientnetv2_l |
| Ubiquant Market Prediction | 2893 | Time series | Regression | Gradient Boosted Decision Trees: - LGBM Neural Networks: - Tabnet |
To sum up, the key skills of Data Scientists with regards to SOTA Machine Learning models are as follows :
- General knowledge which Machine Learning models are currently State of the Art for a range of different use-cases
- Practical, working knowledge with ALL of the SOTA Machine Learning methods allowing to effectively apply them to a task at hand
Critical for:
- Chief Data Scientists
- Data Science Directors
- Data Science Managers
- Senior Data Scientists
- Data Scientists
Resources to improve:
Participation in Kaggle competitions is by far and large the best method to thoroughly improve your Machine Learning skills and become truly intimate with the State of the Art Machine Learning models. Spending time on Kaggle, especially for the Machine Learning beginners, is way more productive for learning Data Science than any other activity.
The most significant benefits of Kaggle for learning Data Science:
- Kaggle is the Stack Overflow of Data Science. We are sorry to break it for you, but in >80% of the cases (a subjective estimate based on our experience), the exact problem you are trying to solve with Machine Learning has already been solved in Kaggle competitions. Even if the problem is coming from a different domain, if you translate it properly into Data Science frameworks, you will realize that it shares the key aspects with already available solutions. When trying to determine which historical Kaggle competition resembles the problem at hand, we suggest using the following table as a heuristic:
| Data Type | Classification | Regression |
|---|---|---|
| Tabular | x | x |
| Time series | x | x |
| Event stream | x | x |
| Video | x | x |
| Text | x | x |
| Sound | x | x |
You should first decide where would you put the x for the problem you are trying to solve, and then look for the exact combination of objective-data type among Kaggle competitions.
- Kaggle is truly state of the art. Top solutions 10 break the current world record according to Jeremy Howard.
- Kaggle accumulates a database of problems with matching solutions with code. However, in order to take full advantage of it, you need to actually participate in a couple of competitions to understand its mechanics.
- Kaggle teaches modesty by allowing you to quickly compare your ideas with “the free market”.
- Kaggle shows how different models work on practical problems
- If you are a competitive person, you will become addicted and it motivate you to go an extra mile and progress quickly
- Kaggle is best to efficiently learn Data Science: first you need to commit a lot of effor to participate on a high level, and after the competition finishes you can read summaries of the top solution with code.
- Compared to reading papers, please consider that for every competition the community has already spent thousands of hours studying papers to get an extra 1%. of their Machine Learning models. .
In order to take full advantage of Kaggle and progress quickly, before you start a competition, you may consider completing the below Machine Learning courses and reading one book. Those resources were cited to me by multiple Kaggle Grandmasters as their introductory journeys to Data Science:
- Fast AI. The AI course by J. Howard and R. Thomas. It is focused purely on Deep Learning - which will not cover all of your use-cases, but in general it is brilliant (in large part because of the teachers).
- The coursera ML course - an overall intro intro Machine Learning by Andrew NG.
- The Elements of Statistical Learning - a book by Trevor Hastie, Robert Tibshirani and Jerome Friedman covering the most important basic theoretical aspects of Machine Learning.
C3b Feature Engineering
Feature Engineering is considered the art of Data Science, as it aims to uncover the hidden signal in the data. The modern feature engineering techniques depend mostly on the data type:
- For images, video, text and sound data, automated feature extraction using Neural Networks have dominated the field of feature engineering.
- For tabular, time series, and event stream data, it is an open question whether to use Neural Networks for automatic feature extraction, or build features manually using heuristics and business insights. Both approaches have pros and cons, as we present below. The typical evolution of Machine Learning systems is to start with manually engineered features + GBDT models to establish a first working system, and then try to beat it with automated feature extraction as the ML system becomes more mature.
This paper offers some intuition on why tree based models outperform deep learning on tabular data.
Manual feature engineering techniques for tabular, time series and event stream data:
- Error analysis
- Driver Tree analysis
- Interviews with industry experts
Comparison of manual vs automated feature engineering for tabular, time series and event stream data
| Criterion | Manual feature engineering + GBDT models | Automated feature engineering using Neural Networks |
|---|---|---|
| Ability to incorporate existing business insights | Yes | No |
| Data preprocessing | Light | Heavy |
| Required data to work | Small | Big |
| Iteriation cycles | Quick | Slow |
| SOTA results | Majority | Minority |
| Guarantee of completeness | No | Yes |
| Benefit from additional training samples | Lower | Higher |
| Scability | Worse | Better |
Resources to improve
- Participation in Machine Learning competitions on Kaggle. Careful analysis of similar competitions typically yields lots of good ideas quickly.
- Air BnB paper on using entity embeddings as features for Gradient Boosted Decision Trees model in a recommender system
Critical for:
- Senior Data Scientists
- Data Scientists
C3c Machine Learning validation and strategic evaluation
Machine Learning validation
Key skills related to Machine Learning validation:
- Understanding the importance of it. Proper validation enables iteration. Without it, you cannot make progress
- Knowing the train - test - validation split mechanics
- Understanding the Target Leak problem
- Understanding that any data you would like to use in train, you need to have available at the exact moment of making predictions
- Understaning various concepts related to different data structures:
- Time based validation
- User based validation
- Stratified validation
Machine Learning strategic evaluation
The most difficult question about Machine Learning and Data Science that you will ever get is often coming directly from the CTO:
- Is our Machine Learning model good or bad?
Answering such a question in a data-driven, non-subjective manner is a skill called Machine Learning evaluation.
Critical for:
- Chief Data Scientists
- Data Science Directors
- Data Science Managers
- Senior Data Scientists
- Data Scientists
Resources to improve
- Participation in Kaggle competitions. Kaggle teaches you to be very rigorous with the validation of your models.
- Benchmarking to your competition. In most cases, you will not know how their models work exactly or what is their accuracy, but you can get surprisingly far by listening to their podcasts or reading their technical blog.
- In some industries, for example Adtech, if you employ your creativity, you can reverse-engineer the exact success rates of your competitors' Machine Learning models and use it as a reference point.
C4 Inference and monitoring of Data Science production systems
Inference is about deploying your models which were trained offline, into an online traffic. Key considerations:
- Feature mismtach between training and inference
- Models complexity - inference determines cost and hence allowed complexity at training time
- Monitoring features distribution over time
- Resolving incidents - - Funnel analysis. looking at the graphs to identify the closest metric influenced by us, and searching slack on correlated deployments.
Critical for:
- Chief Data Scientists
- Data Science Directors
- Data Science Managers
- Senior Data Scientists
- Data Scientists
Resources to improve:
- Libraries focused on improving inference performance. For example, Treelite fo GBDT models.
- Building your own app that handles real time traffic
C5 Long term development & maintenance of Data Science production systems
It is the broad area covering a range of topics related to all aspects of Data Science systems functioning on production. Truly mastering this skill is the most difficult of all ML production skills, in part because the knowledge here is very sparse, and mostly embedded in few large organisations that are running Machine Learnign systems on production long enough to encounter and tackle those problems.
The key Data Science skills related to long-term Data Science technical vision & development:
| Skill | Why difficult |
|---|---|
| Building the Data Science technical vision, and roadmap and prioritising Machine Learning projects. | Truly big ideas cannot be a/b tested without an expensive prior investment. Consequently, the priotization of Machine Learning projects involves application of judgment and is prone to cognitive biases. |
| Deploying New Machine Learning Models that were trained on traffic generated by old Machine Learning models | There are many ways for incumbent ML models to accumulate knowledge which is not transferable into new models during training. It is even difficult to realize the magnitude of the challenge here until you have tried yourself to improve any Machine Learning model that has been deployed on production for a long time. For an in-depth discussion of this topic please see this paper. |
| Servicing data science tech debt | The business orientation on growth typically tramples any other considerations, including reduction of the tech debt. This is magnified by the fact that developing and deploying ML systems is (relatively) fast and cheap, but maintaining them over time is difficult and expensive. Hence, the temptation is always to deploy a new model rather than refactor the code for the old one, leading inevitably to tech debt accumulation. Not all tech debt is bad, but all debt needs to be serviced. This paper discusses it in details. |
Critical for:
- Chief Data Scientists
- Data Science Directors
- Data Science Managers
Resources to improve:
This skills comes mostly from experience, however some practical papers were also published on this topic:
- Pinterest paper on the evolution of their recommender system
- Google ML rules
E1 Industry Knowledge
A vital, yet often neglected enabler for Data Scientists, who benefit much more from industry knowledge compared to e.g. Software Developers. One of the underlying reasons is that Data Science is still a relatively young domain:
- In software development, business analysts/architects are responsible to come up with a solution, and Software Developers are mosly responsible to deploy it
- In Data Science, Data Scientists are responsible for both aspects of the system: conceptual problem framing and deployment as well
When discussing this with senior Data Science leaders the sentiment that often we get is following:
"Learning how the industry works is difficult. Training the model is easy."
Being such a valuable skill, it is used as a distinguishing factor for Data Science candidates in their recruitment process. Especially when trying to land your first Data Science job, industry knowledge acquired through own research and individual projects makes even the junior Data Scientist resume stand out among other candidates.
Critical for:
- Chief Data Scientists
- Data Science Directors
- Data Science Managers
- Senior Data Scientists
- Data Scientists
Resources to improve
- On the job experience: Data Science models built within a particular industry
- Individual projects and research
E2 Coding
Conceptually, coding is not a core data science skill, but rather the measure to tell a computer what you want it to do. In a distant future it might theoretically be replaced by code-free solutions, if they become mature enough. At the moment, however, programming pervades every aspect of Data Science and apt coding skills are vital for proficient Data Scientists. Various programming languanges play their roles at different stages of Data Science systems lifecycle:- Data Preparation and Activation: SQL
- Model Training: Python (Flexibility)
- Inference: Scala / Java / C++ (Scalability)
Critical for:
- Data Science Managers
- Senior Data Scientists
- Data Scientists
Resources to improve:
Courses at datacamp.com and other platforms, which focus on use-cases for Data Science:
E3 Data Science Talent Management & Team Management
Arguably the most important skill for senior Data Science managers. It involves answering the following questions:
- How to attract skilled Data Scientists to the organization? -- Where are the biggest pools of candidates? -- What should the be value proposition of the organization for Data Scientists?
- How should the Data Science recruitment process should like?
- How should the Data Science onboarding look like?
- How should the Data Science career ladder look like?
- What should be the main KPIs for Data Scientists?
- How to keep the Data Science team excited?
- How to resolve conflicts between Data Scientists?
- How to structure the long-term Data Science career progression to align value generated with the total compensation?
- How to prevent churn of the top Data Scientists in the team?
The answer to the above questions depends largely on the context of a given organization, and requires both Data Science skills as well as team management skills.
Critical for:
- Chief Data Scientists
- Data Science Directors
- Data Science Managers
Resources to improve:
This skill comes mostly from experience, therefore the most useful resource here is the experience from reputable Data Science organizations and Data Science senior leaders who are known to do these things well.